In many scenarios, applications integrating Large Language Models (LLMs) need to communicate with external systems or services to obtain information the model does not possess locally. To achieve this integration, we can expose a set of “Cognitive Functions as Tools,” which the LLM dynamically “discovers” and decides to invoke when it detects the need for external information or specific actions.
This integration strategy creates an interaction flow where the model, after processing the initial prompt or context, generates a message (usually in JSON format) describing the invocation of one of these cognitive functions as tools. The host system (the client application) receives this message and:
- Interprets the request.
- Invokes the corresponding function.
- Returns the result to the model so it can complete its response coherently, aligned with the dialogue or the requested task.
Cognitive Functions as Tools refers to specialized functionalities or modules that an AI model can discover and invoke dynamically to access external knowledge, perform specific tasks, or carry out actions that extend beyond its native capabilities.
Table of contents
Open Table of contents
Cognitive Functions as Tools
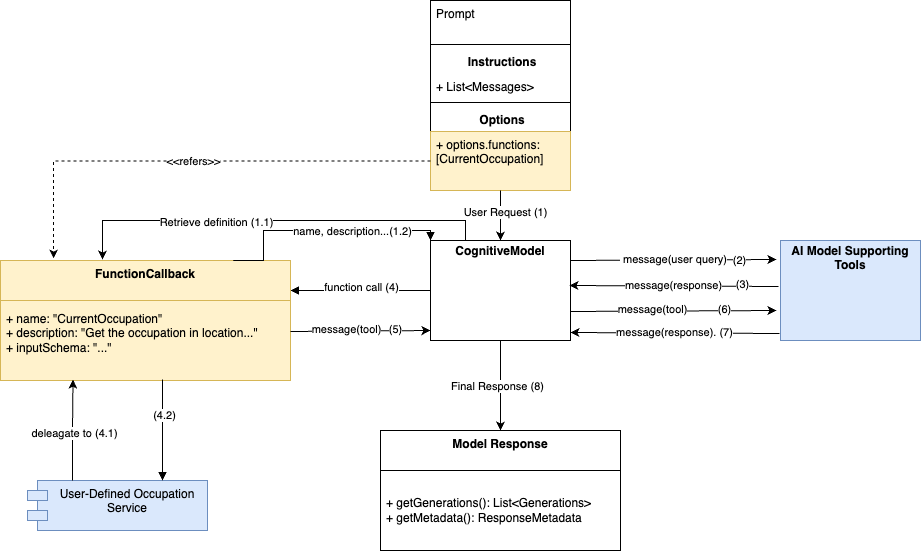
Imagine you have a Digital Twin service that needs extra data from external modules—like a occupation iot sensor. The diagram illustrates a high-level flow:
-
User Request: a user sends a query (“What’s the current occupation in
ZoneX?”). -
Function Definitions: beforehand, each external function (like “CurrentOccupation”) is defined with a name, description, and input schema.
-
Cognitive Model: the central component decides whether it needs to call any function based on the user request. If so, it delegates to the relevant function.
-
Function Callback: this callback acts as a bridge, passing the request to an actual service (a ocupation API, for instance).
-
Response Assembly: once the external data is returned, the chat model combines it into a final answer for the user.
In essence, the diagram shows an architectural pattern where a conversational engine can dynamically invoke external services and seamlessly merge their results into the user-facing response.
Registering custom functions
To enable this dynamic, we define a mechanism for function registration in which:
Each published function exposes:
- Function name: used as an identifier in the invocation message.
- Description: a brief text explaining the function’s purpose.
- Argument specification (typically in JSON schema): describes the data structure the function expects.
The LLM can consult this function catalog to determine if it should call one of them and, if so, constructs a JSON object with the appropriate arguments.
The component architecture or library orchestrating communication with the LLM intercepts that JSON object and triggers the execution of the corresponding function.
This design pattern is inspired by the concept of a “messaging bus” that transfers control from the model (which “requests”) to the host system (which “executes”) without strong coupling between them. The flexibility lies in the fact that the model does not directly invoke the underlying code; rather, it produces the “intention” to invoke in JSON form.
Define a Python function:
def get_current_occupation(location: str) -> dict:
"""
Get the current occupation of a specific location in the city.
Args:
location: The name of the location to check.
Returns:
dict: A dictionary containing the location, the number of people currently there, and the status of the occupation.
"""
# Simulated response (in a real case, this would come from an external API or sensor data)
occupation_data = {
"location": location,
"occupation": 1250, # Example value
"status": "high" # Could be "low", "moderate", or "high"
}
return occupation_dataPass the function as a tool to LLM model:
response = model.chat(
messages=[{'role': 'user', 'content': 'What is the current occupation in Plaza Central?'}],
tools=[get_current_occupation], # Actual function reference
)Call the function from the model response:
# Process function calls from the response
for tool in response.message.tool_calls or []:
function_to_call = available_functions.get(tool.function.name)
if function_to_call:
function_args = tool.function.arguments
print('Function output:', function_to_call(**function_args))
else:
print('Function not found:', tool.function.name)Workflow
- Initial Prompt: the user or an external system formulates a question or request to the LLM.
- LLM Processing: the model analyzes the content of the prompt and decides if it can answer with its own knowledge or if it needs external information.
- Function Necessity Detection: If no external function is required, the LLM responds directly. If it detects a need for external data (current occupation in a given zone of a city), it prepares a JSON message describing a function invocation.
- Function Message Delivery: the model returns a JSON block representing the function call:
{
"name": "getOccupation",
"arguments": {
"location": "ZoneX"
}
}- Invocation in the Host System: the client application parses the JSON, identifies the requested function (getOccupation), and invokes it in its own environment.
- Function Response: the function obtains the information from the external source (a tourism occupation service), processes the response, and returns it to the LLM in the defined structure.
- Completing the Response: the LLM receives these data and produces the final response to the user, incorporating the requested external information.
Architectural Benefits
- Decoupling: the model and the external functions communicate through a contract (function name, description, and JSON schema). This minimizes dependencies between the two components.
- Extensibility: new functions can be added without modifying the model’s internal logic; it’s enough to register new metadata, and the model can start using them as needed.
- Traceability: the flow based on JSON messages simplifies auditing and monitoring, as each exchange (prompt and function-call JSON) can be logged and later reviewed.
- Service Reusability: the same functions can serve multiple purposes and different LLMs or modules, as long as the invocation contracts are maintained.
Implementation Considerations
- Standard Message Format: ensure that the JSON produced by the LLM follows a clear standard and that the application can validate it before processing.
- Error Handling: define what happens if the requested function does not exist, if the JSON is malformed, or if the external service fails. The LLM may need feedback describing the error to steer the conversation appropriately.
- Security: validate and sanitize input parameters coming from the LLM to avoid malicious injections or misuse of registered functions.
- Scalability: when multiple LLMs or multiple instances of the LLM make simultaneous function calls, ensure the infrastructure (load balancers or message queues) handles the load efficiently.