In modern urban environments, data is collected from various domains, including traffic management, public safety or environmental monitoring. This data is typically stored in data lakes, where conventional business intelligence tools are applied to derive insights and facilitate learning. However, a significant challenge in this framework is the siloing of data. This fragmentation requires a tremendous amount of manual effort to connect disparate data sources, often leading to inefficiencies and delays in decision-making processes.
Drawing from the experiences and lessons learned in building distributed architectures at scale over the past decade, a new large-scale data architecture known as data mesh can be adapted for urban data management. Data mesh addresses the inherent challenges of data silos and quality by decentralizing data ownership and governance. In this model, domain-specific teams manage their data as a product, ensuring better alignment with business priorities and more responsive data governance.
Table of contents
Open Table of contents
The role of Digital Twins in data exchange using Data Mesh
A Digital Twin in the city context represents a virtual model of physical assets, processes, and systems. By employing a data mesh architecture, Digital Twins can efficiently exchange data across different domains within the urban environment. This decentralized data management approach ensures that each data source, managed as a product by its respective domain team, provides high-quality, context-rich data that can be readily integrated into the Digital Twin. Consequently, this seamless data exchange enhances real-time monitoring, predictive analytics, and decision-making, thereby improving urban management and the overall quality of life for city residents.
By leveraging the principles of data mesh, cities can create a more integrated and high-quality data ecosystem. This approach enables more efficient data integration, enhances data provenance and quality, and ultimately supports more informed decision-making, fostering a truly data-driven urban environment.
City Data Mesh
Data management is a fundamental necessity for any system, whose components create and consume data. Even stateless applications that generate data need a database that is typically stored in memory or a temporary file. Each component, upon creating data, requires mechanisms to store and manage it efficiently. A database not only facilitates quick access to information but also ensures data integrity and security.
In an urban context, the implementation of a data mesh architecture can transform how information is managed and utilized within a city. This approach supports the entire life cycle of a city, including planning, construction, management, and operations. Unlike the traditional data lake approach, where data is centralized in a single repository, data mesh distributes data responsibility across various specific domains, managed by teams that best understand the data.
Each urban domain, such as traffic, public transport, utilities or waste management, manages its own ‘data as products’. These data products are made available to other domains through a decentralized infrastructure that enables interoperability and real-time data sharing. For instance, data generated by traffic sensors can be managed by the transport team and then shared with other domains to optimize traffic lights and reduce congestion.
Data mesh promotes a more agile and scalable data management approach, allowing autonomous teams to manage and share their data efficiently and securely. This not only enhances operability and efficiency but also drives innovation, enabling different urban domains to develop customized solutions based on their specific needs.
Furthermore, effective data management in the urban environment under the data mesh architecture must ensure data security and privacy, protecting against unauthorized access and ensuring compliance with regulations. Data integrity is crucial for decisions based on the data to be reliable and accurate.
The adoption of a data mesh architecture in a city not only improves operability and efficiency but also creates a smarter and more resilient urban environment, promoting closer collaboration between different domains and fostering sustainable development.
Data interoperability between components in a City Data Mesh
In the context of smart cities, data interoperability between different system components is essential for optimizing urban resources and services. Let’s consider a Digital Twin, a virtual representation of physical assets, processes, or systems, and its interaction with other critical components within this system, such as traffic management (data product A) and urban planning (data product B). Each of these components operates with its own specific database, managing information relevant to its respective functionality.
A Digital Twin exchanges information with these components to enable effective interoperability. For instance, the Digital Twin continuously collects and processes real-time data from traffic management systems (data product A), providing a comprehensive overview of current traffic conditions. This data is then shared with urban planning systems (data product B), facilitating dynamic adjustments that mitigate congestion and enhance traffic flow. Conversely, updates from urban planning, such as new infrastructure projects, are communicated back to the Digital Twin to refine its simulations and predictions.
The implementation of interoperability standards, such as open APIs and standardized communication protocols, is fundamental to facilitating this process. Additionally, the use of advanced data integration technologies, such as middleware and cloud data management systems, ensures that relevant information is available in real-time across all components. This seamless exchange of information not only improves decision-making and coordination but also enhances the overall efficiency and sustainability of urban systems.
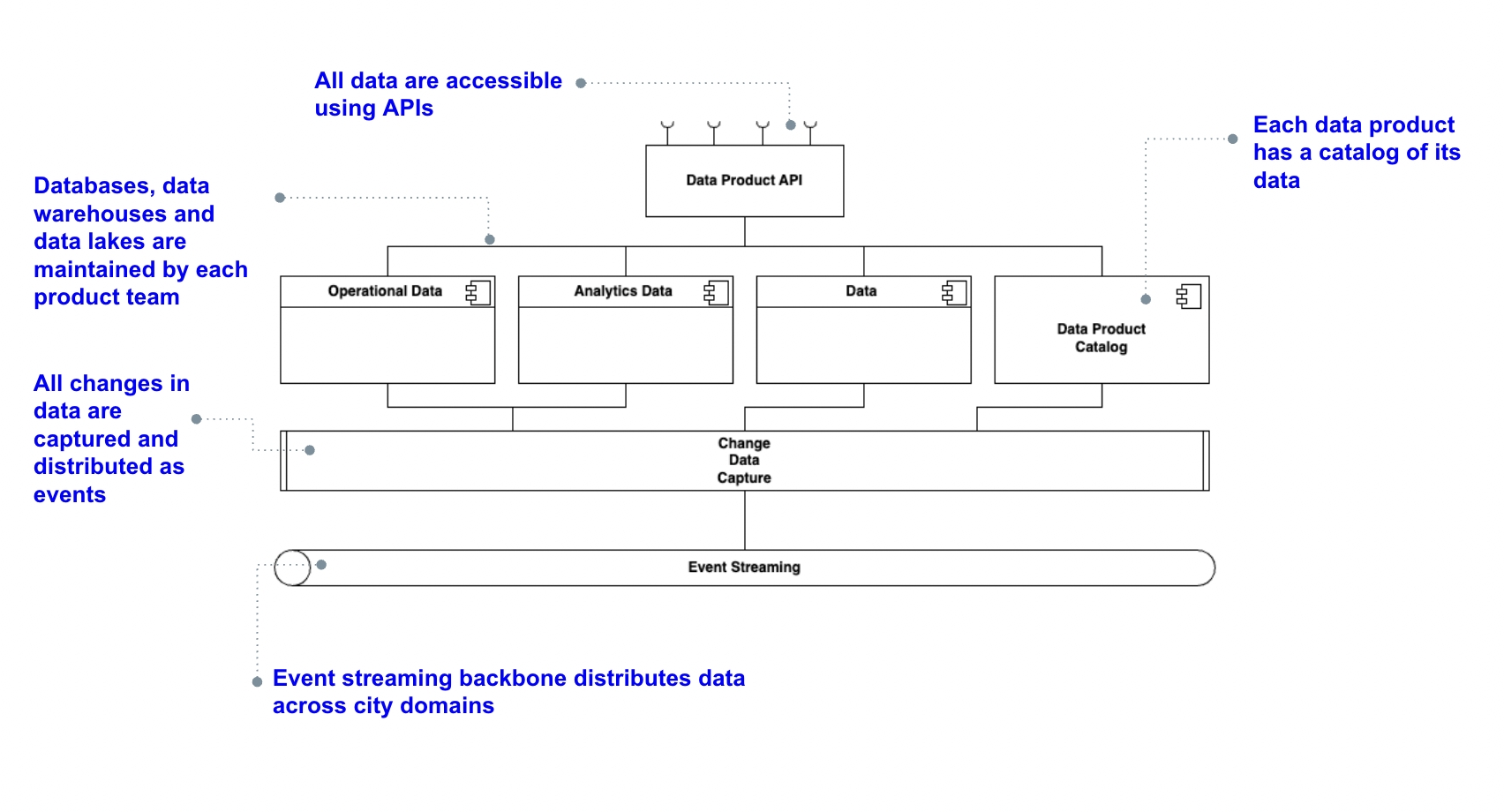
In this architecture, fundamental patterns are adopted to enable advanced data management in a smart city. These patterns include:
Pattern data product catalog
Description: A Data product catalog is a centralized system designed to organize, manage, and provide access to data products within an organization. It enhances data discoverability, operational efficiency, and scalability by offering a user-friendly interface for data discovery and access, ensuring compliance and data quality, and supporting self-service capabilities.
Technical details:
- Metadata repository: stores detailed information about each data product, including name, description, owner, schema, and data quality metrics.
- API Gateway: provides a unified access point for all data product requests, managing authentication, authorization, and routing.
- Registry: tracks all available data products, their versions, and statuses to ensure users can access the latest versions.
- Governance tools: manages data compliance, quality, and policies, providing audit trails and lineage information.
- User interface: a web-based portal that allows users to browse, search, and request access to data products.
- Advanced search capabilities: enables easy discovery of data products through tagging and categorization.
- Role-based access control: manages permissions and access to data products.
- Version management: maintains different versions of data products, allowing rollback to previous versions if needed.
- Usage analytics: monitors data product access, performance, and user interactions, generating reports and dashboards for insights.
- Self-service tools: provides tools for data preparation, integration, and automated data workflows, reducing the need for IT involvement.
Pattern Change data capture
Description: Change Data Capture (CDC) is a pattern used to identify and capture changes made to data in a database, allowing for real-time data integration and synchronization across different systems. It enables organizations to maintain accurate and up-to-date data in various applications and services, supporting real-time analytics, data warehousing, and event-driven architectures.
Technical details:
- Change detection mechanisms: identifies changes through techniques such as database triggers, transaction logs, or timestamp columns.
- Data capture methods: captures changes using approaches like log-based capture, trigger-based capture, or polling mechanisms.
- Data transformation: transforms captured data into a format suitable for target systems, ensuring data consistency and integrity.
- Data delivery: delivers changes to target systems in real-time or near real-time using messaging queues, APIs, or direct database inserts.
- Error handling and recovery: implements mechanisms to handle errors and ensure data consistency, including retry logic and checkpointing.
- Scalability: supports scaling to handle high volumes of data changes, ensuring performance and reliability.
- Monitoring and alerts: provides monitoring tools and alerts to track the CDC process, ensuring timely detection and resolution of issues.
- Integration with data platforms: seamlessly integrates with various data platforms and services, such as data lakes, data warehouses, and streaming platforms.
- Security: ensures secure data capture and transmission, implementing encryption and access controls.
- Data lineage and auditing: tracks the origin and transformation of data changes, providing audit trails for compliance and analysis.
Pattern Event streaming backbone
Description: An Event Streaming Backbone is a foundational architecture pattern designed to handle real-time data streams, enabling the continuous flow and processing of events across an organization. This pattern supports building responsive, scalable, and fault-tolerant systems by facilitating real-time analytics, event-driven applications, and seamless integration of various data sources.
Technical details:
- Event Brokers: centralized systems (such as Apache Kafka, Amazon Kinesis) that ingest, store, and distribute event streams to multiple consumers.
- Producers and consumers: entities that generate events (producers) and those that process or react to them (consumers), connected to the event broker.
- Topics and partitions: logical channels (topics) in the event broker that categorize events, with partitions enabling parallel processing for scalability.
- Stream processing: frameworks (like Apache Flink, Apache Spark) that process and analyze data streams in real-time, performing tasks such as filtering, aggregation, and enrichment.
- Schema registry: a repository for managing and validating the schemas of events, ensuring data consistency and compatibility.
- Data retention policies: configurations that determine how long events are stored in the event broker before being deleted.
- Fault Tolerance and reliability: mechanisms to ensure events are reliably delivered and processed, including replication, acknowledgments, and retry logic.
- Scalability: ability to handle increasing volumes of events by scaling horizontally, adding more brokers, producers, and consumers as needed.
- Security: measures to secure event streams, including encryption, authentication, and access control.
- Monitoring and Management: tools to monitor the health and performance of the event streaming system, with alerts for anomalies and dashboards for real-time metrics.
- Integration capabilities: connectors and APIs to integrate with various data sources and sinks, facilitating seamless data flow across different systems and platforms.
Pattern Data product API
Description: A Data product API is a design pattern that provides standardized and secure access to data products via well-defined APIs. This pattern allows consumers to interact with data products programmatically, enabling seamless data integration, real-time access, and simplified data consumption across various applications and services.
Technical details:
- RESTful or GraphQL API endpoints: provides endpoints for accessing data products, supporting operations like create, read, update, and delete (CRUD).
- API Gateway: a gateway that manages and routes API requests, providing features such as rate limiting, authentication, and load balancing.
- Authentication and authorization: Eesures secure access to data products using OAuth, API keys, or JWT tokens for authentication, and role-based access control (RBAC) for authorization.
- Data serialization: supports multiple data formats (e.g., JSON, XML, Avro) for request and response payloads, ensuring compatibility with different consumers.
- Versioning: implements version control for APIs to manage changes and ensure backward compatibility.
- Caching: caching mechanisms to improve performance and reduce latency for frequently accessed data.
- Rate limiting: controls the number of requests a consumer can make in a given time period to protect against abuse and ensure fair usage.
- Error handling: provides standardized error responses and status codes to help consumers handle issues effectively.
- Documentation and SDKs: includes comprehensive documentation and software development kits (SDKs) to facilitate easy integration and usage by developers.
- Monitoring and analytics: tracks API usage, performance, and health, providing insights through dashboards and alerts for any anomalies.
- Scalability: ensures the API can handle high traffic and large data volumes by scaling horizontally and employing load balancing techniques.
- Integration with backend systems: connects to various backend data sources and services, abstracting the complexity and providing a unified interface for data access.
- Data Transformation and filtering: allows for data transformation, filtering, and aggregation within the API to deliver tailored data responses based on consumer needs.
These patterns integrate to form an city data mesh, where multiple data products, such as traffic data products, tourism, waste, security, and more, can interact and share information efficiently and securely.
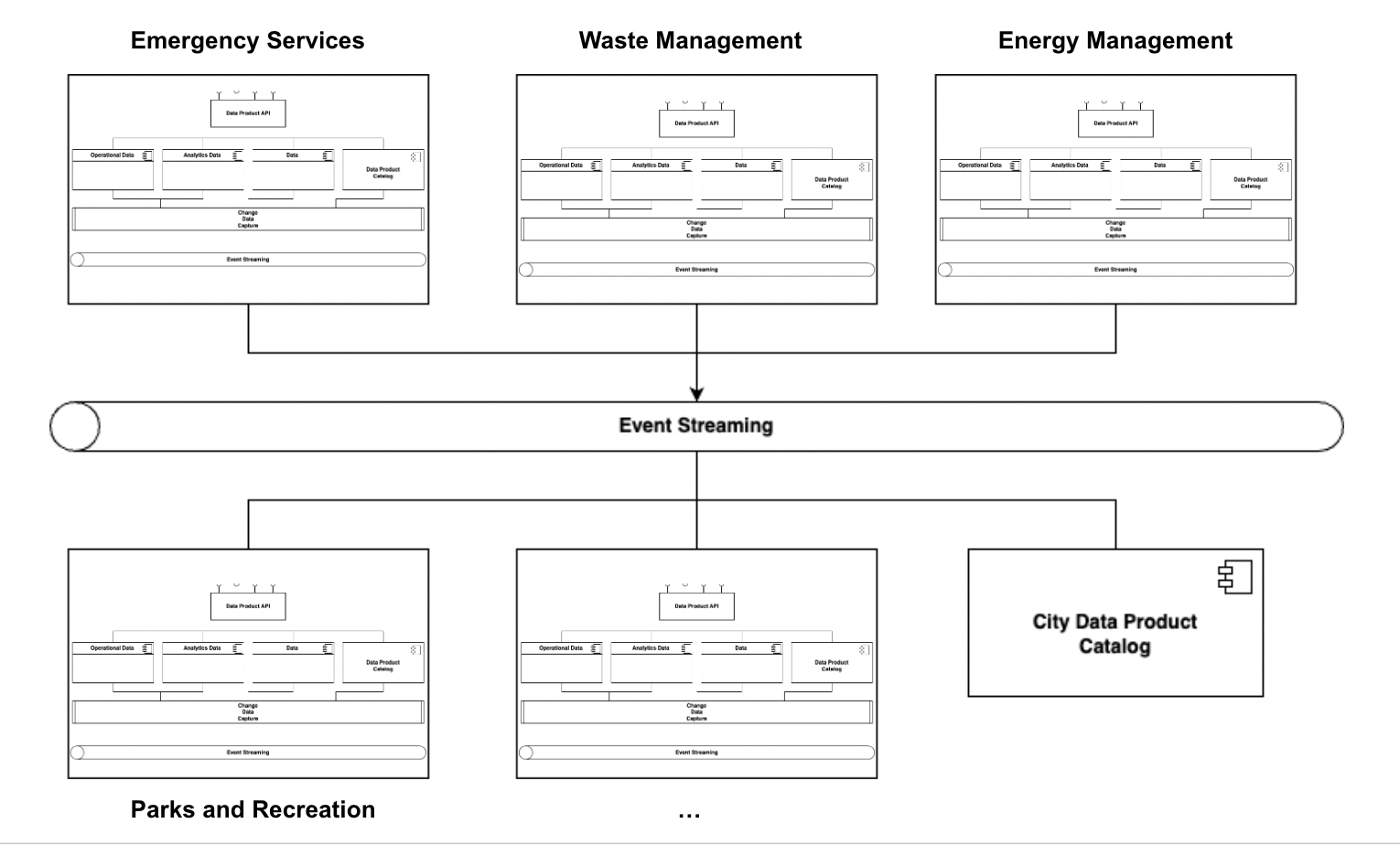
Data interoperability between components not only enhances the operational efficiency of a smart city but also contributes to sustainable development and the quality of life of its inhabitants. The adoption of data mesh architecture patterns ensures that this interoperability is robust, scalable, and aligned with contemporary data management best practices.
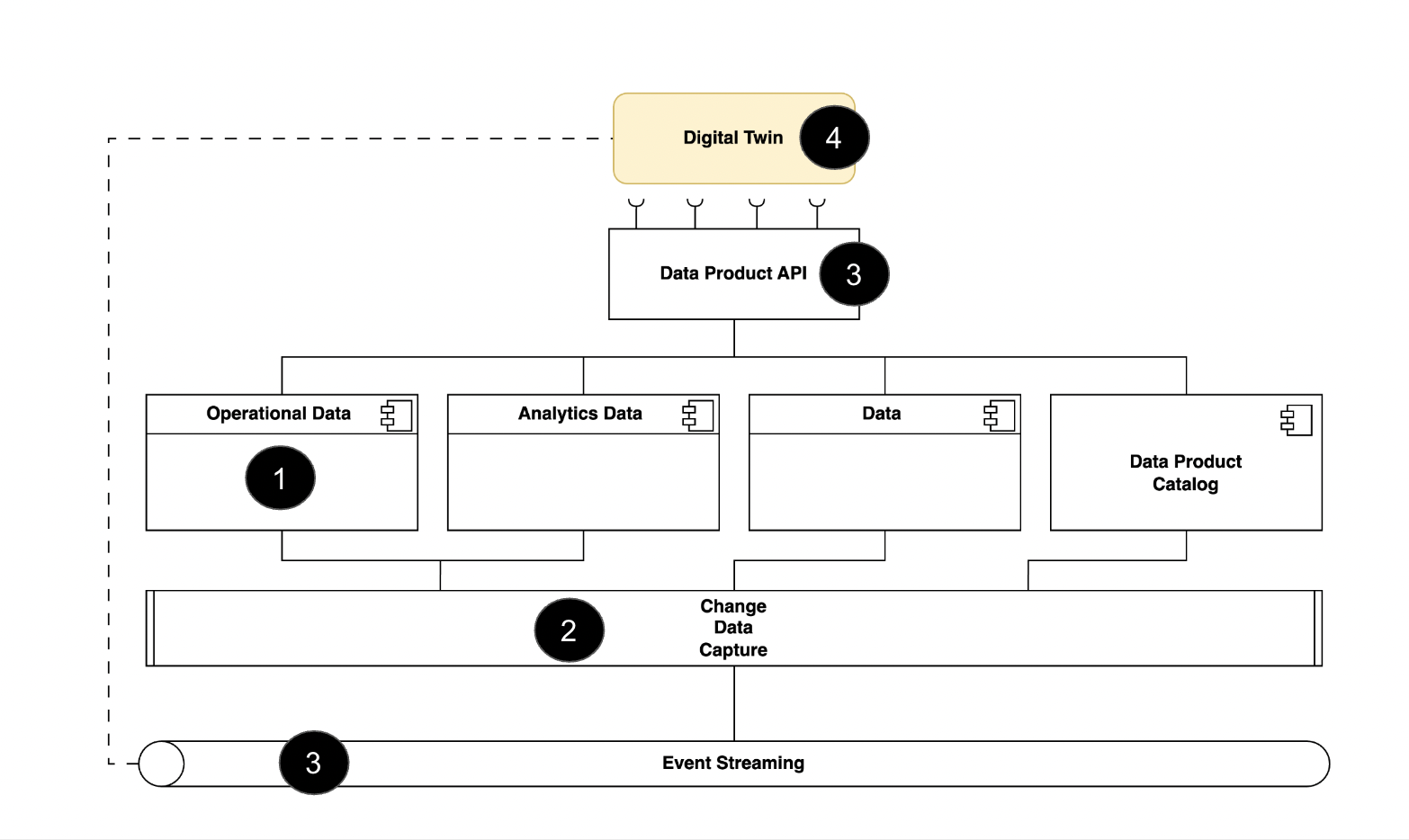
Scenario: Digital Twin integration in a city data mesh.
A critical waste management data product is populated with two-day-old data leading to inefficient planning and operations - The Digital Twin in waste management synchronizes operational data in real-time, leading to optimal management and efficient results.
Digital Twin - one of the many data products within the waste management ecosystem - uses a transactional system and a digital twin to reflect the current state of waste management systems in real-time.
How it works:
- Operational systems update waste management data.
- Change Data Capture (CDC) reads the data and creates a real-time event stream.
- Changes are published to relevant subscribers to optimize waste collection.
- AI/ML models in Digital twin trained with up-to-date data produce optimal results for waste management.
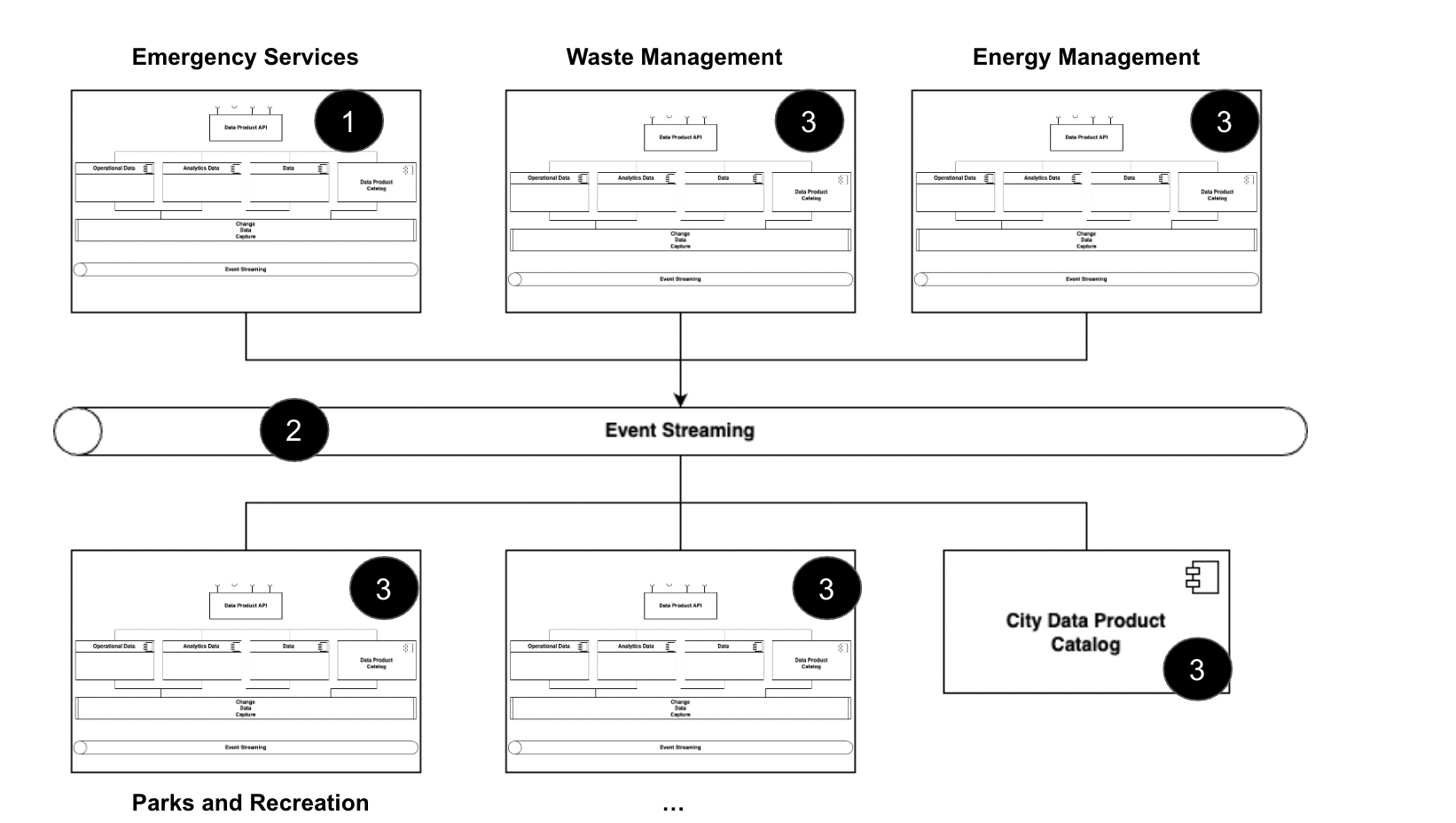
Scenario: City Data Mesh real-Time sync
Real-time data is essential for the efficient operation of a smart city: traffic management systems use it to optimize traffic flow; public safety systems use it for real-time monitoring and response; public transportation systems use it to provide accurate arrival times to commuters.
Changes in city infrastructure and operational data are captured and published as events. The City Data mesh event streaming allows all subscribers - effectively every system in the smart city - to be notified of relevant data changes in real-time.
How it works:
- Smart city systems update infrastructure and operational data. Data Mesh’s Change Data Capture (CDC) reads the data and creates an event in near-real-time.
- Event Streaming (e.g., Kafka) receives data changes and notifies all relevant systems in near-real-time
- Each of these systems can then update their operational data immediately, ensuring the smart city is always current with the latest information.