Designing a Digital Twin is not merely about adding sensors, collecting data, or building dashboards. At its core, it is a challenge of large-scale software engineering: how should we decompose (or not decompose) the system? Which components should be integrated tightly, and which should be decoupled?.
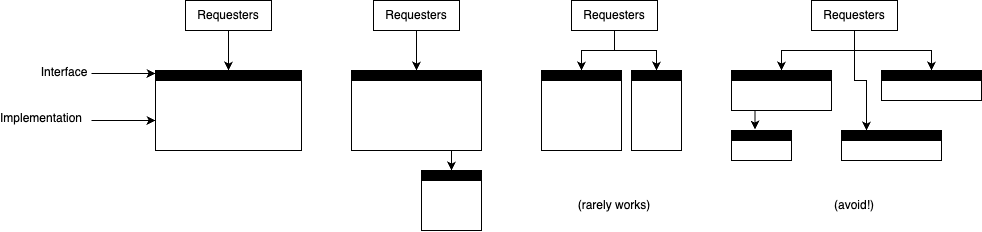
Below, we adapt these key principles to the architectural design of a general-purpose Digital Twin.
Table of contents
Open Table of contents
Reduce overall system complexity
Modularity often appears to be the obvious strategy: break the system into smaller components, each with a well-defined responsibility. However, subdivision also introduces new forms of complexity, such as:
-
Increased number of interfaces between components.
-
Duplicated logic across components.
-
Artificial separation of closely related responsibilities.
Therefore, the key question is not “how much to split?” but rather “where to split in order to reduce total system complexity?”
Bring components together if they share information or purpose
If two components access and process the same contextual data (e.g., spatiotemporal metadata, environmental state, or system events), it might make sense to consolidate them under a shared responsibility. Separating them unnecessarily can introduce redundancy or hinder understanding of their interaction.
When to group responsibilities:
-
When they rely on the same contextual data sources.
-
When one frequently invokes the other.
-
When their interfaces are simplified by co-location.
-
When they cannot be easily understood or used in isolation.
Separate when functional goals or abstraction levels differ
A component responsible for executing internal business logic should not be tightly coupled to one responsible for presenting results to external consumers. While they may share data, their audiences and responsibilities differ, and they evolve on separate tracks.
When to separate components:
-
When one implements reusable logic and the other applies it in a specific use case.
-
When one is internal (e.g., computation engine) and the other is public-facing (e.g., API or dashboard).
-
When they have different lifecycles, scalability requirements, or access patterns.
Split or merge components: structural design decisions
Many architectural flaws arise from poorly defined component boundaries. Just like functions, components must have clear, coherent responsibilities. Poor separation leads to unnecessary coupling, duplication, and confusion.
Key principles:
-
A component should encapsulate a single, meaningful responsibility.
-
Don’t split a component unless doing so simplifies the system’s structure or interfaces.
-
Avoid “conjoined components”—those that are physically separate but logically dependent on each other to the point where one cannot be understood or used without the other.
Applied example: if a component responsible for processing simulation data always requires another to interpret temporal context (e.g., time zone alignment, calendar overlays), consider merging them or redesigning their interface to better encapsulate the responsibility as a whole.
Red flags for architects
🚩 Code repetition: if you see similar logic across multiple components, it’s likely that an abstraction is missing.
🚩 Artificial method coupling: if understanding one component requires digging into another module, you have hidden dependency issues.
🚩 Superficial splitting: if breaking down logic results in trivial, one-liner methods with constant back-and-forth, you’ve added noise, not clarity.
Design for semantic Depth
As the chapter suggests, don’t sacrifice depth in the pursuit of short, modular code. A good system isn’t the most fragmented one—it’s one where each component has meaningful responsibility, a clear interface, and fulfills a complete purpose.
In a Digital Twin architecture, this means designing components like:
-
Context Management – encapsulates spatiotemporal metadata and general system state.
-
Data Acquisition – standardizes how input from sensors, APIs, or other sources is consumed.
-
Simulation & Logic Engine – applies rules, prediction models, or inference mechanisms.
-
Interface Exposure – serves processed outputs to external layers, systems, or users.
Each should fulfill its role without depending unnecessarily on the internal workings of others.