Hallucinations in a language model refer to situations where the model generates responses that, while grammatically correct and contextually coherent, are factually incorrect or entirely made up. Unlike obvious errors, hallucinations can be more challenging to detect because the generated text appears reliable and truthful, which can mislead both users and systems that rely on the model’s accuracy.
Hallucinations in large language models represent a significant challenge to the reliability and safety of artificial intelligence systems. Understanding the fundamental causes and types of hallucinations is essential for developing effective mitigation strategies. Through a combination of improvements in training data, model adjustments, implementation of verification mechanisms, and adoption of advanced patterns, it is possible to significantly reduce the incidence of hallucinations.
Table of contents
Open Table of contents
Common causes of hallucinations
-
Insufficient or irrelevant data: if the model has not been trained on sufficient or representative data, it may generate nonsensical responses.
-
Overgeneralization: models may attempt to generalize patterns from the training data inappropriately, leading to erroneous conclusions.
-
Architectural model errors: sometimes the way a model is architected or trained can lead to the generation of incorrect outputs. These structural issues can induce the model to hallucinate when it encounters unfamiliar scenarios.
Mitigating hallucinations in LLMs with Retrieval-Augmented Generation
It is now widely accepted that the implementation of Retrieval-Augmented Generation (RAG) over Large Language Models (LLMs) significantly enhances their output quality. By integrating external knowledge retrieval mechanisms during the generation process, RAG mitigates the inherent limitations of LLMs, such as hallucination and outdated information. Rather than relying solely on the pre-trained model’s knowledge, RAG dynamically queries relevant data sources in real-time, providing the LLM with up-to-date and contextually accurate information.
While RAG significantly reduces hallucinations by integrating real-time, relevant data during the generation process, it does not completely eliminate them. Factors such as incomplete or biased retrieval sources, errors in query formulation, or limitations in the LLM’s comprehension of retrieved information can still lead to hallucinations.
-
Inefficient information retrieval: when the model retrieves data without effective indexing or metadata, it may miss relevant information or retrieve irrelevant content, leading to hallucinations.
-
Loss of hierarchical context: the model may generate incorrect responses if it fails to consider the hierarchical relationships within data chunks.
-
Unrefined query interpretation: queries that are not properly transformed can lead to misunderstandings by the model, resulting in inaccurate outputs.
-
Limited search capabilities: relying solely on one type of search strategy can cause the model to overlook relevant data.
-
Improper query routing: without directing queries to the appropriate data sources or modules, the model may provide incorrect information.
-
Overlooking contextual windows: if the model does not focus on the specific context surrounding a query, it may generate irrelevant or incorrect answers.
-
Scalability issues with large datasets: as data volumes grow, flat indexing can become inefficient, leading to outdated or irrelevant data being retrieved.
-
Difficulty handling hypothetical scenarios: the model may struggle with hypothetical or deductive reasoning, resulting in hallucinations.
-
Complex query processing needs: when dealing with complex or multifaceted queries, the model might produce incomplete or incorrect responses.
Patterns to mitigate LLM hallucinations
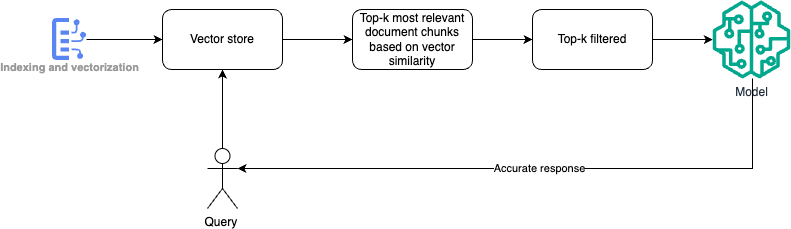
Contextual vector retrieval and generation pattern.
This pattern is used in systems where information retrieval is augmented by AI-generated responses. It combines a search process (retrieving relevant chunks of information based on a query) with natural language generation using AI models like. It is commonly applied in intelligent assistants, advanced chatbots, and search engines.
Problem
In large datasets, simply retrieving documents or information fragments based on a query is not enough to generate contextually rich and accurate answers. Users require generated responses that are both informed by the data and synthesized into coherent, human-like text.
Solution
- Indexing and vectorization convert chunks of documents into vectors and store them in a vector index.
- Query and Retrieval: transform a user query into a vector and retrieve the top-k most relevant document chunks based on vector similarity.
- Contextual filtering: use metadata to further filter the retrieved chunks, ensuring only the most relevant content is considered.
- Answer generation: feed the filtered content into a generative AI model, which uses the retrieved information as context to produce a detailed and accurate response.
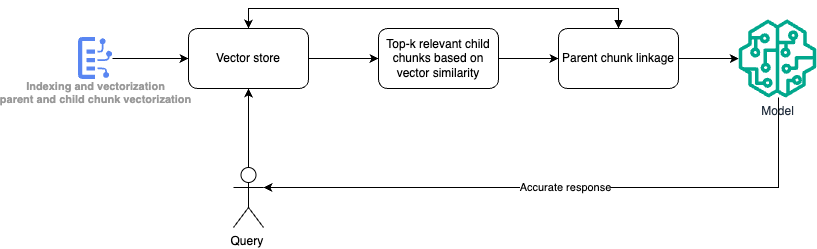
Hierarchical chunk retrieval pattern
This pattern is ideal for systems where hierarchical relationships exist between data chunks, such as parent-child relationships within documents. It applies to contexts where retrieving related sub-chunks (children) and linking them to their parent chunks provides a more complete and contextually accurate answer.
Problem
In large, hierarchical data sets, a single query might return fragmented information without proper context. Retrieving only the most relevant small chunks (children) may lead to incomplete or misleading responses. There’s a need to return both relevant sub-chunks and their parent context to generate more accurate and comprehensive responses.
Solution
- Child chunk vectorization: all sub-chunks or leaves (smallest meaningful data fragments) are vectorized and stored in a vector store for efficient retrieval.
- Query processing: user queries are vectorized, and the system searches for the top-k relevant child chunks based on vector similarity.
- Parent chunk linkage: once the relevant child chunks are retrieved, their parent chunks are also identified and linked to provide a broader context for the information retrieved.
- Answer generation: the generative AI model uses both the retrieved child and parent chunks to generate a contextually enriched and accurate response.
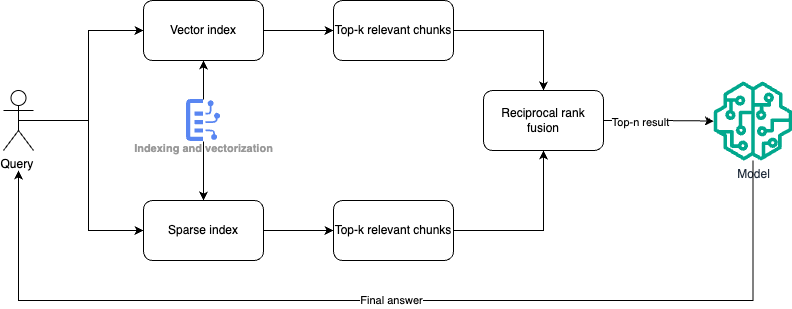
Hybrid search with fusion ranking pattern
This pattern is designed for search systems that combine dense (vector-based) and sparse (traditional keyword-based) retrieval techniques. Hybrid search approaches are particularly effective when attempting to balance the advantages of semantic understanding (from dense embeddings) with the precision of keyword matches (from sparse indices like BM25).
Problem
In information retrieval, relying solely on keyword-based (sparse) methods like BM25 may fail to capture the semantic relationships in queries and documents. On the other hand, dense vector retrieval can provide semantically rich results but might miss exact keyword matches, leading to poor precision in some cases.
Solution
- Dense retrieval (Vector Index): queries and document chunks are vectorized using models like BERT, and stored in a vector index. This allows for semantic retrieval based on vector similarity.
- Sparse retrieval (BM25 Index): the system also uses a sparse index (e.g., BM25) that ranks documents based on traditional keyword matching using n-grams.
- Reciprocal rank fusion (RRF): the results from both retrieval methods (vector-based and sparse) are combined using Reciprocal Rank Fusion, which assigns a ranking score based on the positions of documents in the individual ranked lists. This method ensures a balance between precision (sparse retrieval) and semantic relevance (dense retrieval).
- Top-n result generation: the fused results are ranked, and the top-n relevant chunks are selected to generate the final answer.
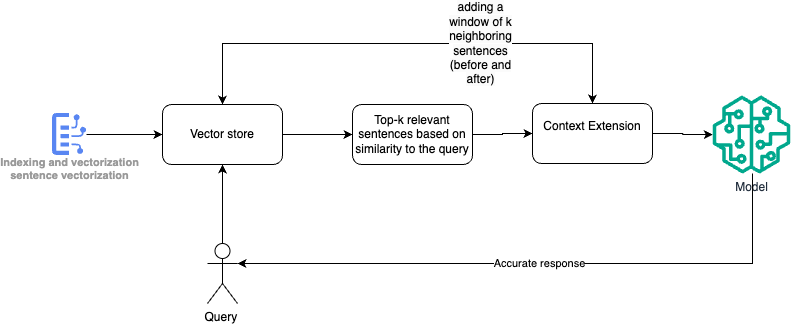
Sentence window retrieval pattern
The pattern is used in systems where retrieving relevant chunks of text based on a query benefits from contextual extension. This pattern is commonly applied in scenarios where the meaning of a sentence or chunk is enhanced or clarified by the surrounding sentences.
Problem
In some cases, retrieving single sentences or small chunks of information based solely on query similarity may result in responses that lack full context. Without surrounding sentences, the retrieved information can be incomplete or ambiguous. There’s a need for a pattern that retrieves not just the exact relevant chunks but also their neighboring sentences, providing additional context to improve the response’s accuracy.
Solution
- Sentence vectorization: all sentences within the document are vectorized and stored in a vector store for similarity-based retrieval.
- Query processing: the system vectorizes the user’s query and retrieves the top-k relevant sentences based on similarity to the query.
- Context extension: For each retrieved sentence, the system extends the context by adding a window of k neighboring sentences (before and after). This allows the system to capture the surrounding information that can help clarify or support the retrieved chunk.
- Answer generation: the generative AI model uses both the retrieved sentence and its contextual window to generate a more complete and accurate response.
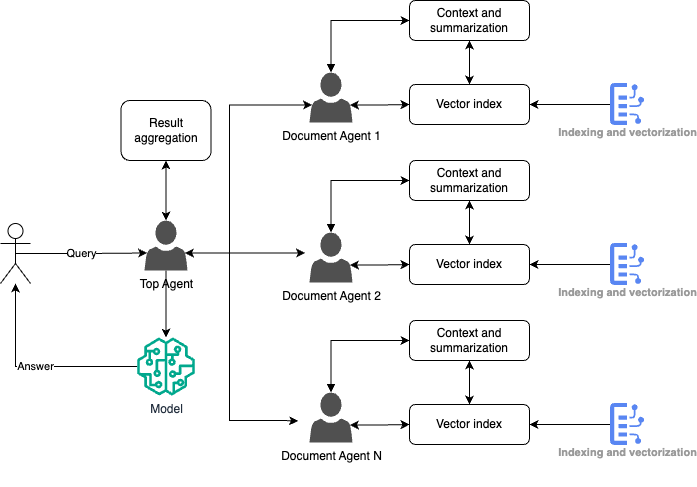
Distributed agent-based query routing pattern
The pattern is designed for complex information retrieval systems where multiple documents or knowledge bases need to be queried independently, and results must be aggregated. Each document or data source is handled by a dedicated agent, and a top-level agent coordinates the query routing and result synthesis.
Problem
In systems with large, distributed datasets, a single retrieval system may not be able to process queries efficiently or return accurate results due to the diversity of data sources. Moreover, querying all data sources simultaneously may not be efficient or necessary. There is a need for a system that intelligently routes queries to the most relevant documents or knowledge bases and aggregates the results into a coherent response.
Solution
- Top agent: the user query is first processed by a top agent, which determines which specific document agents are most likely to have relevant information.
- Document agents: each document agent manages its own set of data, which includes a summary index and a vector index. The agent retrieves the most relevant chunks of information from its assigned document.
- Query routing: the top agent routes the query to the relevant document agents based on the nature of the query and the context each document covers. Each document agent processes the query within its own dataset and returns relevant chunks of information.
- Context and summarization: the retrieved chunks are combined with surrounding context from each document to ensure the information is accurate and well-rounded.
- Answer generation: the top agent aggregates the results from the document agents and generates a final answer, potentially using a generative AI model to summarize and contextualize the retrieved information.