A Retrieval-Augmented Generation (RAG) system is a hybrid AI model that combines the strengths of information retrieval and text generation. It operates by first using a retriever component to search and retrieve relevant documents or data from a large collection based on a user’s query. These retrieved documents are then fed into a generator component, typically powered by a Large Language Model (LLM), which synthesizes the information and generates a coherent, contextually accurate response. This approach enhances the model’s ability to provide informed and precise answers, even when the query involves complex or nuanced information
To conceptualize a RAG (Retrieval-Augmented Generation) architecture using generic software components within a pipeline, it’s essential to understand the key building blocks that drive this process. A RAG system typically involves components that handle various tasks, from retrieving relevant information to generating coherent responses. These components work together in a pipeline, where each step is responsible for a specific function, such as data retrieval, transformation, or response generation.
This approach allows you to build custom RAG pipelines tailored to your specific needs, leveraging the power of large language models (LLMs) and other advanced technologies. From initial prototyping to full-scale deployment, the architecture is designed to be flexible and modular, enabling easy integration and customization. The pipeline composition involves defining each component’s role, how they interact, and ensuring the seamless flow of data through the system.
By focusing on these core concepts, you can create a robust RAG system that is adaptable, efficient, and capable of delivering high-quality results
Table of contents
Open Table of contents
Context
To execute a Retrieval-Augmented Generation (RAG) system, it is essential to first establish a database where the embeddings can be retrieved. Embeddings are typically high-dimensional vectors (lists of floats) that capture the semantic meaning of the text in a way that can be used for further processing.
This database is a populated document store that contains both the original data and their corresponding embeddings, enabling efficient retrieval during the RAG process.
This pre-population of the document store is crucial, as the retriever component in the RAG system relies on the stored embeddings to quickly and accurately retrieve relevant information when generating responses. This setup ensures that the retrieval process is both efficient and scalable, providing a robust foundation for the RAG system’s operations
RAG: generic components
In a Retrieval-Augmented Generation (RAG) system, various components are used, each designed to perform specific tasks within the workflow. These components are often powered by the latest Large Language Models (LLMs) and transformer models, offering advanced language processing capabilities.
From a technical perspective, these components can be typically Python classes with methods that can be directly invoked. To use them, you usually just need to initialize the component with the required parameters and then execute it using a specific method, such as run().
Working at this level with the components of a RAG system is a hands-on and straightforward approach. Each component clearly defines the types and names of its inputs and outputs, allowing for structured and predictable data handling throughout the processing chain. Additionally, the Component API simplifies the creation of custom components, making it easier to integrate external data sources, such as third-party APIs or databases.
An important aspect is that the system validates the connections between components before running the pipeline. If any inconsistencies are detected, it generates error messages with instructions for fixing the issues, ensuring that the system operates optimally.
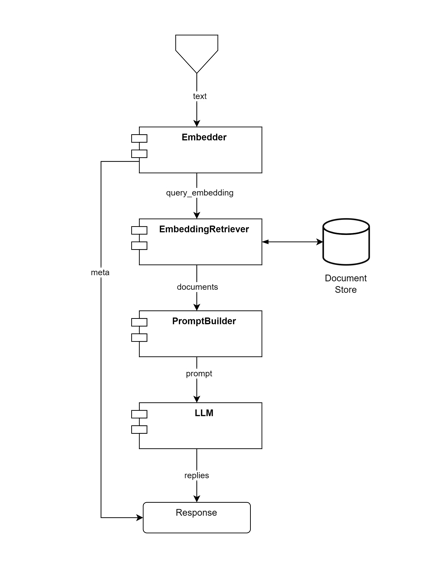
Designing generic software components
Here adapted list from a more generic software perspective, identifying the input parameters and what each component returns
-
Embedder: component that converts the input text into a numerical representation (embeddings).
- Input text (string. Represents any text data input entering the system.
- Output: query embeddings. (List of floats)
This code defines a class Embedder that serves as an illustrative example of encapsulating the functionality of converting input text into a numerical representation using a pre-trained sentence transformer model
class Embedder:
def __init__(self, model_name='all-MiniLM-L6-v2'):
"""Initializes the Embedder with a pre-trained model."""
self.model = SentenceTransformer(model_name)
def get_embeddings(self, text):
"""
Converts input text into a numerical representation (embeddings).
Parameters:
text (str): The input text to be converted.
Returns:
List[float]: The embedding vector representation of the input text.
"""
embeddings = self.model.encode(text)
return embeddings.tolist()-
EmbeddingRetriever: component that retrieves relevant information based on the generated embedding.
- Input: embedding (List of floats). Represents the numerical representation of the input text.
- Output: Documents (List of documents)
Databases that support embedding-based operations, such as OpenSearch, can be used as the underlying document store. By implementing the DocumentStore interface’s abstract methods (query_by_embedding and write_documents) to interact with a specific database
class EmbeddingRetriever:
"""
Class that encapsulates the functionality of an embedding-based retriever.
This class is generic and not tied to a specific document store implementation.
"""
def __init__(self, document_store):
"""
Initializes the EmbeddingRetriever with a generic document store.
:param document_store: Document store that supports embedding-based search.
"""
self.document_store = document_store
def retrieve(self, query_embedding):
"""
Retrieves the most relevant documents based on embedding similarity.
:param query_embedding: Embedding vector of the query.
:return: List of relevant documents.
"""
documents = self.document_store.query_by_embedding(
query_embedding=query_embedding
)
return documents- PromptBuilder: constructs a prompt based on documents and other optional inputs.
- Input: documents (List of documents), template (optional), template_variables (optional).
- Output: Prompt (string)
class PromptBuilder:
basic_template = (
"Based on the following documents:\n{documents}\n"
"Please provide a response for this question:\n{query}\n"
)
def __init__(self, template=None, template_variables=None):
"""
Initializes the PromptBuilder with an optional template, template variables, and model.
:param template: A string template with placeholders for variables.
:param template_variables: A dictionary of variables to fill into the template.
"""
self.template = template or self.basic_template
self.template_variables = template_variables or {}
def build_prompt(self, documents, query):
"""
Constructs the prompt based on the documents and the template and variables.
:param documents: List of document strings.
:param query: The query string.
:return: A prompt string.
"""
combined_documents = "\n".join(documents)
self.template_variables['documents'] = combined_documents
self.template_variables['query'] = query
try:
prompt = self.template.format(**self.template_variables)
except KeyError as e:
raise ValueError(f"Missing template variable: {e}")
return prompt- LLM: Language model generator that produces an output based on a given prompt.
- Input: prompt (string). Represents the prompt generated by the PromptBuilder.
- Output: the responses generated by the system based on the provided prompt. (string)
import openai
from llama_cpp import Llama
class LanguageModelGenerator:
def __init__(self, model, **kwargs):
self.model = model
if model == 'openai':
openai.api_key = kwargs.get('api_key')
self.model_name = kwargs.get('model_name', 'gpt-3.5-turbo')
elif model == 'llama':
self.llm = Llama(model_path=kwargs.get('model_path'))
else:
raise ValueError("Unsupported model")
def generate(self, prompt):
if self.model == 'openai':
response = openai.ChatCompletion.create(
model=self.model_name,
messages=[{"role": "user", "content": prompt}]
)
return response['choices'][0]['message']['content'].strip()
elif self.model == 'llama':
output = self.llm(prompt)
return output['choices'][0]['text'].strip()
else:
raise ValueError("Unsupported model")
** Meta: additional information associated with data processing and response generation.
Connecting the components
The components in a RAG system are connected in a pipeline that defines the flow of data and operations. This pipeline orchestrates the execution of each component, ensuring that the output of one component serves as the input for the next. By defining the sequence of components and their interactions, you can create a robust and efficient RAG system that delivers high-quality results.
The following pseudo code snippet demonstrates how to connect the components in a RAG pipeline using the generic software components defined earlier. In this example, we initialize each component with the required parameters and execute them in sequence to generate a response based on a user query.
template = "Based on the following context:\n{documents}\nPlease provide a response for this question:\n{query}\n"
rag_pipeline = Pipeline()
embedder = Embedder()
retriever = EmbeddingRetriever(document_store)
prompt_builder = PromptBuilder()
generator = LanguageModelGenerator(model='openai', api_key='YOUR_API_KEY')
rag_pipeline.add_component(instance=embedder)
rag_pipeline.add_component(instance=retriever(document_store=doc_store, top_k=3), name="retriever")
rag_pipeline.add_component(instance=prompt_builder(template=prompt_template), name="prompt_builder")
rag_pipeline.add_component(instance=generator, name="llm")
rag_pipeline.connect("embedder", "retriever.retrieve")
rag_pipeline.connect("retriever.documents", "prompt_builder.build_prompt")
rag_pipeline.connect("prompt_builder.prompt", "llm.generate")
question = "How temperature and rain affects cultural heritage in august?"
result = rag_pipeline.run(
{
"embedder.get_embeddings": {"text": question},
"prompt_builder": {"question": question},
"llm": {"generation_kwargs": {"max_tokens": 128}
}
)
generated_answer = result["answers"][0]
print(generated_answer.data)